
How modern SEO crawlers render JavaScript and why traditional HTML crawling is no longer enough
Modern websites don’t really behave like websites used to.
A few years ago, most pages delivered everything directly inside the HTML source. If you opened “View Source”, what you saw was basically what search engines saw too. That made technical SEO fairly straightforward — crawl the HTML, analyse links and metadata, fix problems, done.
Today though, a huge number of websites load content using JavaScript frameworks like React, Vue, Angular, or custom client-side scripts. Pages often appear almost empty at first load and only become complete after scripts run inside the browser.
This shift has quietly created one of the biggest challenges in technical SEO: traditional crawlers don’t always see what search engines actually see.
And that’s where JavaScript rendering comes in.
What JavaScript rendering actually means
When an SEO crawler performs a basic crawl, it usually downloads the raw HTML response from a server and analyses that content. This works perfectly for static websites, but modern sites often build parts of the page dynamically after loading.
For example:
- navigation links might appear only after scripts execute
- page titles may change dynamically
- product listings load via API requests
- internal links are injected into the DOM later
- redirects happen through JavaScript instead of server responses
If a crawler only reads the initial HTML, it may completely miss these elements.
JavaScript rendering changes this process by loading pages inside a real browser engine, allowing scripts to execute before analysis begins. In other words, the crawler waits until the page finishes rendering — similar to how a user (and search engines) experience it.
That difference sounds small, but in practice it changes everything.
Why traditional crawling sometimes gives incomplete results

A common situation many site owners run into is this:
You crawl a site and everything looks fine, but pages still struggle to index or internal links don’t seem to pass authority properly.
Often the issue isn’t visible in raw HTML at all.
Modern frameworks frequently rely on client-side rendering, meaning important SEO signals only exist after JavaScript runs. Without rendering support, a crawler might report:
- missing content that actually exists
- pages appearing nearly empty
- fewer internal links than Google discovers
- incorrect metadata
- unexplained crawl gaps
This leads to confusion because the audit looks clean, yet rankings or indexing behave strangely.
Search engines like Google render pages before indexing them, so analysing only pre-render HTML is increasingly disconnected from real-world behaviour.
How SEO crawlers have adapted
Over time, several SEO tools introduced JavaScript rendering to close this gap. Tools like Screaming Frog and Sitebulb added rendering modes that use browser engines to simulate how pages load in reality.
The trade-off, however, is that rendering is resource-heavy. Running a browser engine for every page significantly increases processing requirements, which is why some tools limit rendering usage, slow crawl speeds, or require additional configuration.
Rendering has traditionally felt like an “advanced” feature rather than part of normal crawling.
But that’s starting to change as JavaScript-heavy sites become the default rather than the exception.
CrawlRhino SEO Crawler now supports JavaScript rendering
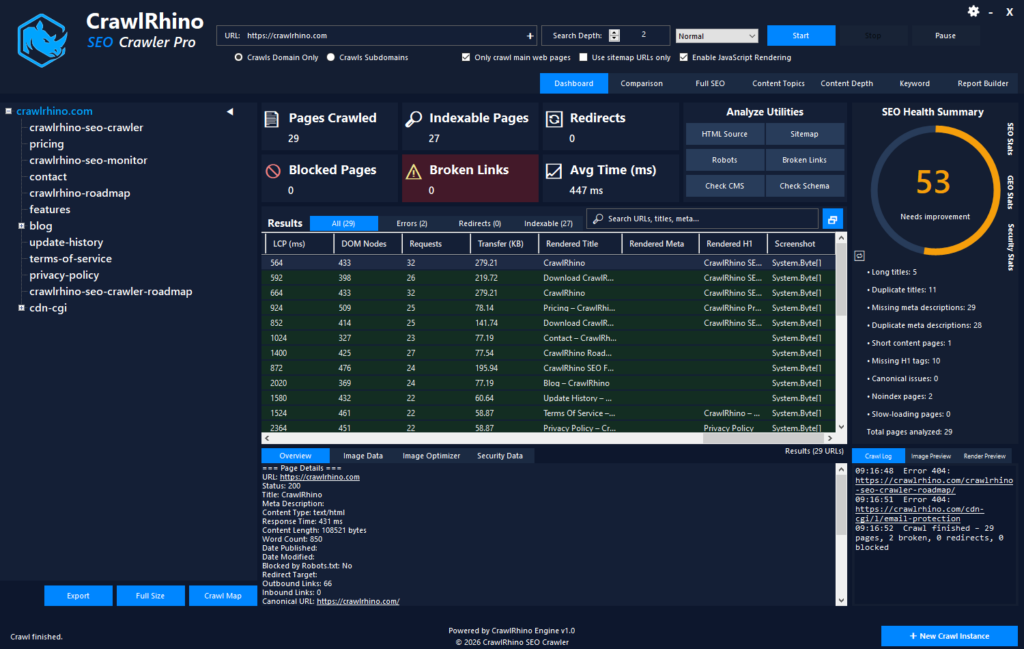
With version 1.1.20, CrawlRhino SEO Crawler introduces full JavaScript rendering powered by a Chromium browser engine.
Instead of analysing only the initial HTML response, CrawlRhino now loads each page in a headless Chromium environment and captures the fully rendered DOM — essentially analysing the page after scripts have finished executing.
This allows the crawler to detect things that previously remained hidden, including dynamically generated content, JavaScript redirects, and links inserted after page load.
What’s important here is that rendering runs locally on Windows, meaning there are no cloud credits or usage limits tied to analysis. The crawl behaves much closer to a real browsing session while still keeping the performance advantages of desktop software.
For websites built using modern frameworks, the difference in crawl accuracy is noticeable almost immediately.
What JavaScript rendering helps uncover
Once rendering is enabled, entirely new categories of issues become visible.
Pages that previously appeared empty may suddenly contain full content structures. Navigation systems generated by scripts become crawlable. Metadata that changes dynamically can finally be analysed correctly.
Common discoveries include:
- internal links only visible after rendering
- delayed content affecting indexability
- JavaScript-based redirects
- incorrect canonical handling after page load
- performance slowdowns caused by scripts
These are problems many site owners don’t realise exist because they never appear in traditional crawls.
Introducing the Full Data Explorer

Alongside rendering support, CrawlRhino Version 1.1.20 also introduces a new Full Data Explorer, which honestly feels like a needed addition once crawls start getting large.
Anyone who has analysed a big site knows how quickly datasets become overwhelming. Thousands of URLs, filters everywhere, and suddenly finding one issue becomes harder than fixing it.
The new workspace separates data exploration from the main crawl view and adds live filtering that updates instantly as you type. Instead of exporting data or digging through menus, you can isolate problems in seconds — errors, redirects, slow pages, canonical issues, all without refreshing views.
There’s also an active filter indicator showing exactly what’s applied, which sounds small but actually prevents a lot of confusion when analysing large crawls.
It makes investigation feel more fluid rather than spreadsheet-heavy.
Why JavaScript rendering is becoming essential for SEO
The reality is simple: websites have changed faster than many SEO workflows.

If a crawler cannot analyse rendered pages, audits increasingly reflect only part of the picture. As more sites rely on dynamic content delivery, rendering support moves from “advanced feature” to basic requirement.
This doesn’t mean traditional crawling disappears — raw HTML analysis is still useful — but combining both approaches provides a far more accurate understanding of how search engines interpret a website.
JavaScript rendering bridges that gap.
Desktop crawlers still have an advantage
Interestingly, while many SEO platforms now run entirely in the cloud, desktop crawlers still offer something important when rendering enters the workflow: control.
Rendering locally means:
- no usage credits consumed
- no crawl quotas tied to server costs
- immediate testing after fixes
- freedom to experiment without limits
Cloud tools remain excellent for monitoring and reporting, but for technical investigation, being able to rerun crawls freely often leads to better problem solving.
Many SEO professionals end up using both approaches depending on the task.
Final thoughts

JavaScript rendering isn’t just a new feature checkbox — it represents a shift toward analysing websites the way modern search engines actually process them.
As frameworks and dynamic content continue to grow, crawlers that rely only on static HTML analysis will increasingly miss important technical signals.
With Version 1.1.20, CrawlRhino SEO Crawler moves into this next phase by combining Chromium-based rendering with a workflow designed for local analysis and deeper data exploration.
If you’ve ever run a crawl and felt like something didn’t quite add up, rendering is often the missing piece.
You can download the latest version of CrawlRhino SEO Crawler here